Un compilador toma como su entrada un programa escrito en
lenguaje fuente y produce un programa equivalente escrito lenguaje objeto. Un
compilador se compone internamente de varias etapas o fases que ser realizan
operaciones lógicas:
Análisis Semántico: Semántica de un lenguaje dar sentido
a sus construcciones, como los tokens estructura y sintaxis. Semántica ayudan a
interpretar los símbolos, sus tipos y sus relaciones con los demás. Análisis
semántico los jueces si la sintaxis estructura construida en el programa de
origen se deriva el significado o no.
CFG + semantic rules = Syntax Directed Definitions
Por ejemplo:
int a = “value”;
No debe emitir un error léxico y la sintaxis en fase de análisis, ya que es léxico y estructuralmente correcto, pero se debe generar un error semántico como del tipo de asignación es diferente. Estas normas están definidas por la gramática de la lengua y evaluado en análisis semántico. Las siguientes tareas deben realizarse en análisis semántico:
- Resolución de Ámbito
- Comprobación de tipos
- Matriz de control
Errores Semanticos
Hemos mencionado algunos de los errores que la semántica analizador semántico se espera para reconocer:
- No coinciden los tipos
- Variable no declarada
- Identificador reservado uso indebido.
- Declaración de variables múltiples en un ámbito.
- Acceder a una variable fuera de alcance.
- Parámetro formal y real no coincide.
Gramatica Atributo
Atributo gramática es una forma especial de libres de contexto gramática donde algunas de las informaciones adicionales (atributos) se añade a una o más de sus terminales con el fin de proporcionar información sensible al contexto. Cada atributo tiene bien definido el dominio de los valores, como integer, float, caracteres, cadenas y expresiones.
Atributo gramática es un medio para proporcionar semántica en el contexto de libre gramática y puede ayudar a especificar la sintaxis y la semántica de un lenguaje de programación. Atributo gramática (cuando se considera como un árbol de análisis) puede pasar valores o información entre los nodos de un árbol.
Ejemplo:
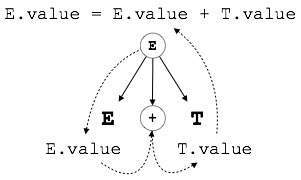
E → E + T { E.value = E.value + T.value }
La parte derecha de la CFG contiene la semántica las normas que especifican el modo en que la gramática debe ser interpretado. Aquí, los valores de las terminales E y T se suman y el resultado se copian en el no-terminal E.
Semántica atributos pueden ser asignados a sus valores de su dominio en el momento de análisis y evaluación en el momento de la cesión o condiciones. Sobre la base de la forma los atributos obtienen sus valores, que pueden dividirse en dos categorías: atributos sintetizados y atributos heredados.
Atributos sintetizados
Estos atributos obtener los valores de los atributos de sus nodos secundarios. Para ilustrar, asumir las siguientes producciones:
S → ABC
Si S es tomar los valores de sus nodos secundarios (A,B,C), entonces se dice que es un atributo sintetizado, como los valores de ABC se sintetizan para S.
Como en nuestro ejemplo anterior (E → E + T), el nodo padre E obtiene su valor de su nodo hijo. Sintetiza los atributos nunca tomar valores entre sus nodos padres o cualquier nodos relacionados.
Atributos heredados
A diferencia de los atributos sintetizados, atributos heredados puede tomar valores entre padres y/o hermanos. Tal como se muestra en la siguiente producción,
S → ABC
Puede obtener los valores de S, B y C. B puede tomar valores de S, A, y C. Asimismo, C puede tomar valores de S, A y B.
Expansión: se produce cuando un no-terminal se ha ampliado a los terminales, como por una regla gramatical
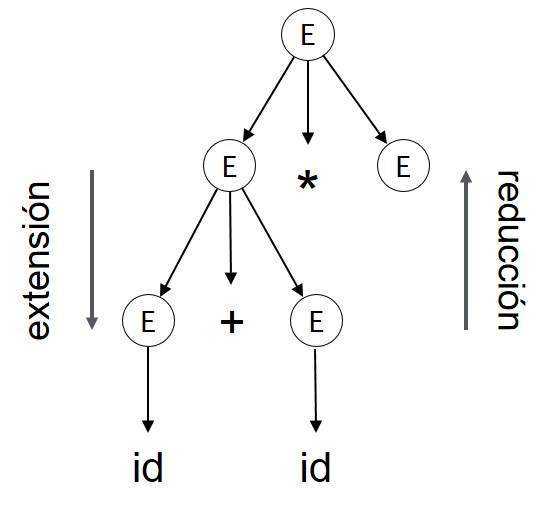
Reducción: Cuando un terminal se reduce a su correspondiente no-terminal según las reglas de gramática. Los árboles se analizan Sintaxis de arriba a abajo y de izquierda a derecha. Reducción cada vez que se produce, sus reglas semánticas correspondientes (acciones).
Análisis semántico utiliza la sintaxis dirige las traducciones para realizar las tareas antes mencionadas.
Analizador semántico recibe AST (Abstract Syntax Tree) de su etapa anterior (sintaxis).
Analizador semántico concede información sobre los atributos de AST, que son llamados atribuido AST.
Los atributos son dos tupla valor, <nombre de atributo, valor de atributo>
Por ejemplo:
int value = 5;
<type, “integer”>
<presentvalue, “5”>
Para cada producción, damos una regla semántica.
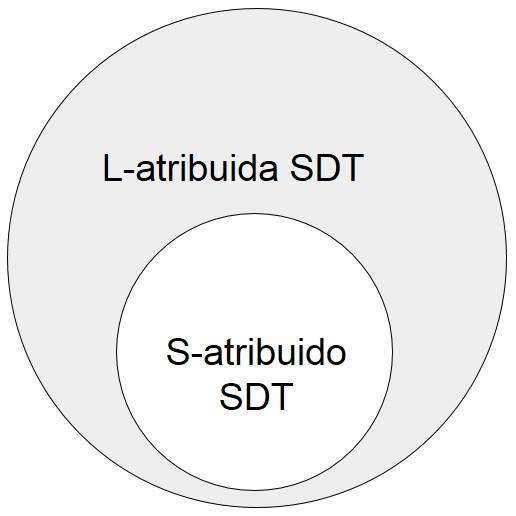
S-atribuyó SDT
Si un TRATO ESPECIAL Y DIFERENCIADO sólo utiliza atributos sintetizados, se llama como S-atribuidas al SDT. Estos atributos son evaluados usando S-atribuidas SDTS que tienen sus acciones semánticas escrito después de la producción (a la derecha).
Tal como se ha descrito anteriormente, los atributos de S-atribuidas SDTs son evaluados en la parte inferior de análisis, como los valores de los nodos padres dependen de los valores de los nodos secundarios.
L-atribuyó SDT
Esta forma de SDT de ambos atributos sintetizados y heredados con la restricción de no tomar los valores de derecha hermanos.
En L-atribuidas SDTs, un no-terminal pueden obtener los valores de su padre, hijo, y nodos relacionados. Tal como se muestra en la siguiente producción
S → ABC
S puede tomar valores de A, B y C (sintetizada). UNA puede tomar valores de S. B puede tomar valores entre S y A. C se puede obtener los valores de S, A y B. No Hay terminal puede obtener los valores de los hermanos a su derecha.
Los atributos de L-atribuidas SDTs son evaluados por primero en profundidad y de izquierda a derecha el análisis.