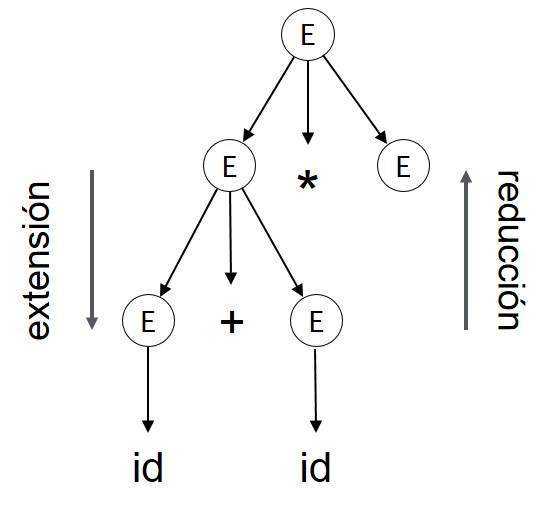
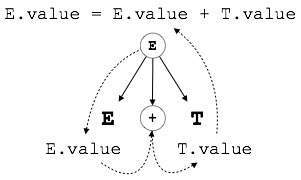
En el modelo de
análisis y síntesis de un compilador, la etapa inicial traduce un programa
fuente a una representación intermedia a partir de la cual la etapa final
genera el código objeto. Los detalles del lenguaje objeto se confinan en la
etapa final, si esto es posible. Aunque un programa fuente se puede traducir
directamente al lenguaje objeto, algunas ventajas de utilizar una forma
intermedia independiente de la máquina son:
1. Se facilita la redestinación; se puede crear un
compilador para una máquina distinta uniendo una etapa final para la nueva
máquina a una etapa inicial ya existente.
2. Se puede aplicar a la representación intermedia un
optimizador de código independiente de la máquina.
• Se busca: –
transportabilidad
–
posibilidades de optimización
• Debe ser: –
abstracto
– sencillo
• No se tiene en
cuenta: – modos de direccionamiento
– tamaños de datos
–
existencia de registros
–
eficiencia de cada operación
|
Código Intermedio
|
|
Ventajas
|
Desventajas
|
|
– Permite abstraer la máquina, separar operaciones de alto nivel de
su implementación a bajo nivel.
– Permite la reutilización de los front-ends y backends.
– Permite optimizaciones
generales.
|
– Implica una pasada más para el compilador (no se puede utilizar el
modelo de una pasada, conceptualmente simple).
– Dificulta llevar a cabo optimizaciones especí- ficas de la
arquitectura destino
– Suele ser ortogonal a la
máquina destino, la traducción a una arquitectura específica será más larga e
ineficiente.
|
Tipos de Código Intermedio
AST (Abstract Syntax Trees): forma condensada de árboles de
análisis, con sólo nodos semánticos y sin nodos para símbolos terminales (se
supone que el programa es sintácticamente correcto).
DAG (Directed Acyclic
Graphs): árboles sintácticos concisos
TAC (Three-Address Code): secuencia de instrucciones de la
forma: – operador: aritmético / lógico – operandos/resultado: constantes,
nombres, temporales.
TAC
• Ensamblador general
y simplificado para una máquina virtual: incluye etiquetas, instrucciones de
flujo de control…
• Incluye referencias explícitas a las direcciones de los
resultados intermedios (se les da nombre). • La utilización de nombres permite
la reorganización (hasta cierto punto).
• Algunos compiladores generan este código como código
final; se puede interpretar fácilmente (UCSD PCODE, Java)
Representaciones de TAC
Fuente: a := b * c + b * d;
Cuádruplas: el destino suele ser una temporal.
(*, b, c, t1)
(*, b, d, t2)
(+, t1, t2, a)
Tripletas: sólo se representan los operandos
(1) (*, b, c)
(2) (*, b, d)
(3) (+, (1), (2))
(4) (:=, (3), a)
Tripletas Indirectas: + vector que indica el orden de
ejecución de las instrucciones.
a := (b * c + b * d) * b * c;
Notaciones
• Las notaciones
sirven de base para expresar sentencias bien definidas.
• El uso más extendido de las notaciones sirve para expresar
operaciones aritméticas.
• Las expresiones aritméticas se pueden expresar de tres
formas distintas: infija, prefija y postfija.
• La diversidad de notaciones corresponde en que para
algunos casos es más sencillo un tipo de notación.
• Las notaciones también dependen de cómo se recorrerá el
árbol sintáctico, el cual puede ser en inorden, preorden o postorden; teniendo
una relación de uno a uno con la notación de los operadores.
Infija
• La notación infija
es la más utilizada por los humanos por que es la más comprensible ya que ponen
el operador entre los dos operandos. Por ejemplo a+b-5.
• No existe una
estructura simple para representar este tipo de notación en la computadora por
esta razón se utilizan otras notaciones.
Postfija
• La notación postfija pone el operador al final de los dos
operandos, por lo que la expresión queda: ab+5-
• La notación posftfija utiliza una estructura del tipo LIFO
(Last In First Out) pila, la cual es la más utilizada para la implementación.
Prefija
• La notación prefija pone el operador primero que los dos
operandos, por lo que la expresión anterior queda: +ab-5. Esto se representa
con una estructura del tipo FIFO (First In First Out) o cola.
• Las estructuras FIFO son ampliamente utilizadas pero
tienen problemas con el anidamiento aritmético.
Generación de código para las estructuras de control
Una vez sabemos cómo
generar código para las expresiones y asignaciones, vamos a ver cómo podemos
generar el código de las estructuras de control. Hay dos estructuras que ya
hemos visto implícitamente. Por un lado, la estructura de control más simple,
la secuencia, consiste simplemente en escribir las distintas sentencias una detrás
de otra. En cuanto a las subrutinas, bastara con crear el correspondiente prologo
y epílogo según vimos en el tema anterior. Las sentencias de su cuerpo no
tienen nada especial. A continuación veremos algunas de las estructuras más
comunes de los lenguajes de programación imperativos. Otras estructuras se
pueden escribir de forma similar.
EL CÓDIGO P
El código P comenzó como un código ensamblador objetivo
estándar producido por varios compiladores Pascal en la década de 1970 y
principios de la de 1980. la descripción de diversas versiones de código P.
La máquina P está compuesta por una memoria de código, una
memoria de datos no especificada para
variables nombradas y una pila para datos temporales, junto cualquier registro
que sea necesario para mantener la pila y apoyar la ejecución.
Como primer ejemplo se considera la expresión:
— La versión de código P para esta
expresión es la que se muestra en seguida:
ldc 2 ; carga la
constante 2
lod a ; carga el
valor de la variable a
mpi ;
multiplicación entera
lod b ; carga el
valor de la variable b
ldc 3 ; carga la
constante 3
sbi ; sustracción
o resta entera
adi ; adiciona de
enteros
Esta
instrucción se ven como si representaran
las siguientes operaciones en una maquina P
En primer lugar, ldc 2 inserta el valor 2 en la pila
temporal. Luego, lod a inserta el valor de la variable a en la pila. Las instrucción mpi extrae estos
dos valores de la pila, los multiplica (en orden inverso) e inserta el
resultado en la pial. Las siguientes dos instrucciones (lod b y ldc 3) inserta
valor de b y la constante 3 en la pila (ahora tenemos tres valores en la pila).
Posteriormente, la instrucción sbi extrae los dos valores superiores de la
pila, resta el primero del segundo, e inserta el resultado. Finalmente, la
instrucción adi extrae los dos valores restantes de la pila, los suma e inserta
el resultado. El código final con un solo valor en la pila, que representa el
resultado del cálculo.
IMPLEMENTACIÓN DEL CÓDIGO P
Históricamente, el código P ha sido en su mayor parte generado como un archivo de texto, pero
las descripciones anteriores de las
implementaciones de estructura de datos internas para el código de tres
direcciones (cuádruples y triples)
también funcionara como una modificación propia para el código P.
GENERACION DEL CODIGO PARTIENDO DE LI. ALGORITMOS:
Se sabe que entre el parse y el lenguaje objeto resultado de
la compilación, habrá una de estas dos cosas o ambas.
·
Un lenguaje intermedio LI.
·
Una generación de código.
Se supone la existencia de ambos componentes, nos hace falta
ahora el regresar el código objeto para la maquina objeto deseada, que en el
caso normal de no tratarse de un compilador cruzado, es el mismo código con el que
está escrito el compilador.
Como ejemplo de las posibilidades existentes se mencionan
las de la figura 5 para el lenguaje pascal.
Se emplea in código P para un maquina hipotética que opera
con una pila. Este compilador es muy portable de una maquina a otra. Es el
método usado en el USCD PASCAL que al estar todo escrito en el código de la
maquina ficticia P, sólo se precisa tener un pequeño interprete distinto para
cada maquina objeto dada.
Pero la hipotética maquina a pila, ya nos es tan hipotética
puesto que ahora existe ya como microprocesador, con lo que el código P se
ejecuta directamente.
También es como el primer caso, pero en vez de emplear un
interprete, se traduce con un ensamblador para la maquina objeto dada.
·
El compilador puede dar directamente un módulo
cargable para la maquina objeto en cuestión.
·
El compilador suministra un objeto responsable
que se puede montar con otros objetos.
Para dar concreción vamos a definir el conjunto de
instrucciones de un ordenador sencillo que tenga sólo un acumulador A y un
registro índice X. Una instrucción simbólica con un ensamblador para esta
maquina tendría hasta 4 partes separadas entre si por blancos:
-Una parte opcional, la etiqueta.
-El código de operación.
-El operando.
-Comentario opcional.
La forma de direccionar la memoria son las siguientes:
DIRECTA: Se toma como operando el contenido en memoria del
campo de dirección.
INDIRECTA: Como antes pero, el contenido de memoria se
considera a su vez como dirección del dato.
INMEDIATA: El valor de la dirección lo tomo inmediatamente
como operando.
Y salvo en el caso del direccionamiento inmediato, las
direcciones pueden ser: Absolutas o reales, Relativas a la instrucción actual,
Indexadas con un registro.